模拟面向对象
C 语言虽然没有面向对象,但是 OOP 的思想,在管理大型工程里,已经是思想钢印了
所以嘛,你可以看到很多 C 库在尽力模仿 OOP
首先用 typedef 定义“对象”
typedef struct{
...
} Class_Name;然后写方法,方法形参包含一个指向结构体的指针
int func(Class_Name* obj, ...){
obj->first_var = ...;
}你也可以写一个 init 方法,不过就是不会自动调用
(结构体定义时,内部成员无法赋初始值,即直接写等于 0,这是标准 C 的规则,而 C++ 允许了这点,C 类似于声明内存布局,而 C++ 类似于声明一个类)
在主函数里构造“对象”,调用方法
int main(){
Class_Name myObj;
i nt result = func(&myObj, 100);
}不过面向对象的编程语言一般支持多态、继承等其他特性
内存分配
本质是在<stdlib.h>中(C++ #include <cstdlib>)
void* calloc (int num, int size);
void* malloc (int num);
void* realloc (void* addr, int newsize);
void free (void* addr);分配的 int 都是按字节分配 然后 callloc 分配后,初始化为 0,malloc 不初始化
char* name;
name = (char*)malloc(30*sizeof(char));
name = calloc(20, sizeof(char));C 语言中,由于返回void*,可以自动转换其他类型指针,不用非得写强制类型转换。 但是在 C++中不行,必须写。
sizeof 是 C/C++ 的一个一元运算符,不是函数(虽然看起来像),因为它在编译期就决定了结果
sizeof 可以计算 变量 或者 类型 的大小,返回的是字节的个数
sizeof(int);
sizeof(char*);
sizeof(x);
sizeof(void (*) (int)); //在 32 位机得到 4int arr[10];
sizeof(arr); //40
//这是在获取一个变量的大小
int* p = arr;
sizeof(p); //4
//也是在获取变量的大小在 C++中,使用 new 和 delete,是不需要引入东西的,它是一个关键字
在 C++中,使用智能指针,引入的是<memory>
memcpy 和 memset
这两个函数,不推荐引入 C memory.h 来用,而是引入 string.h 来使用(前者过于古董)
这两个函数,都是按照字节开操作数据的
前者拷贝还好说,问题是后者,后者是给“某个地址开始”,“多长”,“每个字节都设置同一个什么值”
对于 int 来说,它是 4 字节,而你如果每个字节设置同一个值,那肯定不是一个合理的 int,除非这个值是 0 或 -1
即: memset(arr, 1, sizeof(arr)) 会让一个 int 变成 0x01010101,并不是你想象的 1
预处理器指令
#define
C 的宏有两种,一种是常数一种是函数
define identifier string
define func(arg1, arg2) <expression>1、常数定义的宏,可以没有 string。没有 string 的在编译时,identifier 将被替换为空串。identifier 将保持“被宏定义”的状态,以便于用#ifdef #if defined 测试
2、函数宏可以用 反斜杠 \ 来换行。函数建议用 () 包裹整个表达式,不然可能求值顺序出问题。
条件编译
不是检查 identifier 其值是否为 0,而是查看其定义情况
#if defined(CREDIT)
credit();
#elif defined(DEBIT)
debit();
#else
printerror();
#endifif 后面必须有 endif 来匹配。ifdef 是 if defined 的缩写,所以也需要 endif
if 后不仅仅可以放置 define,还可以进行常规的条件判断
#if expressionif 后面可以放的是 define 或者 常量表达式,如 ARG > 1。if 允许嵌套使用。
#undef 可以取消之前对 identifier 的定义。 语法:#undef identifier
预定义宏
__cplusplus
__FILE__
__STDC_NO_THREADS__
__STDC_VERSION__
_MSC_VER # msvc 版本号,用于检测当前编译器是否为 msvc
_WIN32 # Microsoft 专用,当目标架构为 32 位时为 1
_WIN64
__MINGW32__例子:
#if defined(__cplusplus)
extern "C" {
#endif
/*your code here*/
#if defined(__cplusplus)
} /* end extern "C" */
#endif(1)如果我用 gcc 编译,__cplusplus不会被定义;如果用 g++编译,则__cplusplus会被定义
(2)这段代码是 C 和 C++混合编程中常见的一种模式,用于确保 C++编译器以 C 的方式处理特定的代码。extern "C"在 C++代码中,extern "C"告诉编译器这段代码应当按照 C 语言的规则进行编译和链接,而不是 C++的规则。 C 是一个字符串,被双引号包裹
例子:
#if defined(__MINGW32__) || defined(_MSC_VER)
#define DLLImport __declspec( dllimport )
#define DLLExport __declspec( dllexport )
#else
#define DLLImport /* extern */
#define DLLExport /* nothing */__declspec(dllexport)和__declspec(dllimport),这是 Microsoft Visual C++(MSVC)编译器特有的关键字,用于指定函数或变量是从 DLL 中导出还是导入。在 MinGW 环中,这些关键字也被支持。在非 WINDOWS 上,它们被定义为空,表示没有特殊行为。
__declspec()的括号内可以放很多种东西,比如 dllimport,noinline
是** declaration specification**(声明规范)的缩写
例子(使用__declspec):
在 h 和 cpp 文件中,均要在函数前加 DLL_API
// ExampleDLL.h
#ifdef EXPORTING_DLL
#define DLL_API __declspec(dllexport)
#else
#define DLL_API __declspec(dllimport)
#endif
DLL_API void MyExportedFunction();// ExampleDLL.cpp
#include "ExampleDLL.h"
DLL_API void MyExportedFunction() {
// 实现。..
}#include "ExampleDLL.h"
int main() {
MyExportedFunction();
return 0;
}不定义 EXPORTING_DLL,DLL_API 将解析为 __declspec(dllimport)
GCC 例子: 对于 GCC,处理共享库(在 Linux 中通常是.so文件)时,你可以使用__attribute__((visibility("default")))和__attribute__((visibility("hidden")))来控制符号的导出和隐藏
// ExampleLibrary.h
#ifdef EXPORTING_DLL
#define DLL_API __attribute__((visibility("default")))
#else
#define DLL_API
#endif
DLL_API void MyExportedFunction();
// ExampleLibrary.c
#include "ExampleLibrary.h"
DLL_API void MyExportedFunction() {
// 实现。..
}
#include "ExampleLibrary.h"
int main() {
MyExportedFunction();
return 0;
}__declspec(dllexport)不只是可以导出函数,变量,类,好像都行 这个东西放在函数声明的哪个位置都行,不过建议是头部 就是这样也行
返回类型 __declspec(dllexport) 函数名(参数列表) {
// 函数体
}#pragma pack(push,8) 设置 struct 或者 union 的内存对其方式,提高访存效率,增大内存占用
指针
指针数组
int* a[10]; //10 个指针
const char* names[4]={"zhao","qian","sun","li"};关于为什么会对char* n[4]产生疑惑? 因为int*指向的是一个 int,解引用之后一定是一个 int,但是不关心,是否这个 int 是一个单独的 int,还是一个数组的首元素
int x=10;
int y[2]={3,6};
int* p[2]={&x,y};char*解引用后,如果你当作数值去计算,也是一个单独的 char printf、scanf 函数,如果使用%s,那么参数应该是char*类型
char **指针
光有字符串不行,需要字符串数组
char* names[4]={"zhao","qian","sun","li"};
//实际上这个 names 就是 char**
char** p = names;在函数形参使用char**,可以让其具备处理多个字符串的能力 注意这个内存分配
char** dynamicArray = malloc(rows * sizeof(char*));
// 分配一个数组,每个元素的大小是 char *的大小,返回其首地址
for (int i = 0; i < rows; ++i) {
dynamicArray[i] = malloc(columns * sizeof(char)); // 为每行分配字符数组,dynamicArray 的每个元素的类型就是 char*
}const 指针
指向不准备修改的量的指针,指向位置不可变的指针
const int *p1; //指向的数据不能改(通过该指针),指针可指向另一个东西,然后修改它也不是不行
//这和函数接收指向常量的指针一样
//即 *p1 是不可修改的 p1 可指向另一个东西
void fun(const char* str);//表示我们不准备在这个函数中修改这个指针指向的内容
//本质,只是有一个 const 的变量,它作用域是在这个函数内
int const *p2; //等效上一个,一般不用
int * const p3;
//指向指向的地址是固定的,即指针的值定死了,指向的东西可修改函数指针
函数指针指向了一个函数,提供了另一种调用函数的方法。可是,为什么不直接使用函数名呢?这就要提到回调函数了。对于写底层库的程序员和写应用的程序员,他们之间是不沟通的,因此他们互相无法知晓对方写的函数叫什么名字,如果写库的程序员写了一个函数,但是这个函数需要调用到写应用的程序员的函数,才能发挥作用,他就需要预留一个函数指针位置,将来写应用的程序员把指针传进去。
我们要分清: 指针变量 p 指针类型 int* 函数指针类型 Opetator 函数指针变量 p 函数类型、签名 当我们提到指针时,一般指的是变量。
函数指针的声明: return_type (*pointer_name)(parameter_type1, parameter_type2, ...);
int max(int x, int y)
{
return x > y ? x : y;
}
int (* p)(int, int) = & max; // &可以省略函数指针作为函数的形式参数类型:和声明一个函数指针是一样的,就好像 int a 既可以在函数形参那里,也可以在函数内。只不过换一个位置罢了。
void populate_array(int *array, size_t arraySize, int (*getNextValue)(void))
{
for (size_t i=0; i<arraySize; i++)
array[i] = getNextValue();
}
// 获取随机值
int getNextRandomValue(void)
{
return rand();
}
int main(void)
{
int myarray[10];
/* getNextRandomValue 不能加括号,否则无法编译,因为加上括号之后相当于传入此参数时传入了 int , 而不是函数指针*/
populate_array(myarray, 10, getNextRandomValue);
for(int i = 0; i < 10; i++) {
printf("%d ", myarray[i]);
}
printf("\n");
return 0;
}使用 typedef 简化函数指针的使用: 本质是定义了函数指针类型
typedef int (*Operation)(int, int);
int performOperation(int a, int b, Operation op) {
return op(a, b);
}理解:typedef 中声明的类型在变量名的位置出现
int a;
typedef int my_int;
int (* p)(int, int);
typedef int (* op) (int, int);
typedef int array_t[10];
array_t myarray;有的程序会这样写:
typedef int (func_t)(int a, int b);
func_t *fp = sum;或者
typedef const char* fmi2GetTypesPlatformTYPE(void);
//与 (* fp) 等价看这个函数指针类型到底是啥:
struct OpenModelicaGeneratedFunctionCallbacks sp_callback = {
(int (*)(DATA *, threadData_t *, void *)) sp_performSimulation, /* performSimulation */
(int (*)(DATA *, threadData_t *, void *)) sp_performQSSSimulation, /* performQSSSimulation */
sp_updateContinuousSystem, /* updateContinuousSystem */
sp_callExternalObjectDestructors, /* callExternalObjectDestructors */
NULL, /* initialNonLinearSystem */
};类型是int (*)(DATA *, threadData_t *, void *)但是你不能typedef 返回值 (*)(参数列表) Name,只能typedef 返回值 (* Name)(参数列表),后者是符合 C 的变量定义的。typedef 和变量定义一样。
函数返回或参数为指针
函数形参是指针,已经比较熟悉了
int func(int* p);如果函数要返回指针
int* func();但是,C 语言不支持在调用函数时返回局部变量的地址,除非定义局部变量为 static 变量
双指针
virtual HRESULT SetParent(IRoDmDataObject* i_pParent) = 0;
virtual HRESULT GetParent(IRoDmDataObject** o_ppParent) = 0;这里,显然是这个类,有一个指向 parent 的指针
并且一定是一个指针,而不是对象,否则父亲就属于自己了
那么 set 的时候,必然也要传递一个地址进去
get 的时候,要求一个双重指针,然后解引用,把自己的父亲赋进去
修饰性关键词
存储类
存储类定义 C 程序中变量/函数的存储位置、生命周期和作用域。
这些说明符放置在它们所修饰的类型之前。
auto register static extern 是 C 中四个可用的存储类。
C++中,auto 有自己的用途。
定义在函数中的变量默认为 auto 存储类,不用显示写出。
register int a; 表示可以将 a 这个变量存入寄存器,而不是放在内存里,提高访问速度。
在 C++中,register 已经明确为弃用,只是为了兼容性,依然支持这样写,但是编译器根本不管。
static(存储类)
static:静态的
你联想 java 的 public static void main,就能明白 static 并不是常量的意思
当用 static 修饰全局变量/函数时,就意味着该变量只能在本源文件中使用,变得不能跨文件了,extern 找不到它
(不然,你在头文件定义的全局变量,include 之后在哪都能用,或者不 include,使用 extern 找到即可使用)
当 static 修饰局部变量时,将变量的空间分配到静态区,而不需要在每次它进入和离开作用域时进行创建和销毁
void func1(void)
{
/* 'thingy' 是 'func1' 的局部变量 - 只初始化一次
* 每次调用函数 'func1' 'thingy' 值不会被重置
*/
static int thingy = 5;
thingy++;
printf(" thingy 为 %d , count 为 %d\n", thingy, count);
}(全局变量和 函数内部的 static 变量都是存放在静态区) https://www.runoob.com/w3cnote/c-static-effect.html
重点:
如果两个不同的文件定义了同名的 static 全局变量,它们实际上是完全独立的变量,彼此之间不会互相干扰。
在使用全局变量时,优先考虑将它们设置为 static 通常被认为是更好的编程习惯。
并且,一般不在函数里使用 static
extern(存储类)
extern 表示某个全局的变量定义在其他编译单元中,另一种 include 罢了,但只 include 这一个 当使用 extern 关键字时,不会为变量分配任何存储空间,而只是指示编译器该变量在其他文件中定义 或者 extern void someFunction(); 引入函数 不过一般不建议在。h 文件里定义变量,可能会导致重定义问题
例子: gcc a.c b.c 时,他们是两个独立的编译单元,生成不同的 .o 文件 由于没指定参数,gcc 默认要链接再生成可执行文件
当你在 a.c 写一个变量,b.c 用 extern 引入,如果你只是用 gcc b.c 是不行的 这是因为,寻找 extren 变量的规则导致的,在编译时,编译器将 extern 变量认为是在别的编译单元里,因此你能通过编译,但是,在链接时,由于没编译 a,会报链接错误。正确做法是 gcc a.c b.c 这样,把这个变量单独的编译到一个编译单元里,通过 extren 在另一个编译单元中找到它。
很明显,你把这个变量写到 a.h 里,不写 include,gcc b.c 是不可行的。因为你压根没编译这个变量。你 gcc a.h b.c 也不行。(这不废话,.h 只是复制黏贴) 所以,整个过程给你一种,extern 会去其他 c 文件里找变量的感觉。
为什么要使用 extren,是因为比如说,你在头文件里声明一个函数,一个变量,然后写上 pragma once。然后去一个 c 文件,include 头文件,并实现这个函数。再在主文件里 include 头文件,调用这个函数。 显然 gcc main.c func.c 在链接时,会报 x 重定义问题。因为 include 实际上是赋值代码片段,那么 x 实际上在两个编译单元分别都被编译了。即便是你不在头文件里写变量,你在 c 文件里写一个全局 x,再在主文件写一个全局 x,最后还是会链接错误。实际上错的点是一样的。 这也就是说,两个编译单元中的全局变量,最终会放到同一个静态区,不允许重名。所以需要使用 extern 来引入别的编译单元中的全局变量。 (此时,你在 func.c 给 x 加上 static 也不行,会报一个 warning)
为什么,我同时在 main.c fun.c 中写一个 int x; 做全局变量,最后链接时会错误。而再两个文件中同时 include <stdio.h>,则不会产生错误? 是因为 stdio.h 中只包含函数声明(宏定义,类型定义),最后由链接器去找到这个函数,也许它们早就编译好了,都不需要再编译,反正它给能给你自动链接到。
所以如果头文件不包含变量定义,只有函数声明,宏,类型定义,实际上用#pargma once 或 #ifndef, #define, #endif 是无所谓的,用了能够提高编译效率。
如果你使用标准库 stdio.h,它之所以可以多次引入,是因为其不包含变量的定义。然后,编译器被设计成,不需要用户指明 C 标准库的目标文件的位置,就可以链接到它,所以,给了你一种错觉,就是你使用头文件,会让头文件被编译,实际上并不是。只有标准库,标准库都编译好了,下载编译器就有。
对于使用 extern 引入函数。写一个新头文件,让两个源文件同时包含它,是更好的做法。不过是等级的。
实际上根本问题在于编译链接运行,java 虽然也要编译,但是编译后,生成字节码就运行,而 C 要链接。 头文件和 C 文件只是人为的划分,真正有影响的是编译单元。各个编译单元之间互不知道任何信息,如果想利用别的编译单元的函数,只能靠头文件统一各个接口的调用规则,声明函数表明了如何压栈。
define
以#号开头的命令称为预处理命令(编译之前)比如#include #define #ifndef #endif 等 #define a b
带参数宏定义 #define 宏名(形参,形参) 表达式 其中宏名和(之间无空格,否则会认为是常规宏 #define SQUARE(x) ((x) * (x))
通过思考#define __MATH_H__,可以想到,第一个参数被替换成第二个参数,第二个参数可以不存在
这个与 typedef 不同,typedef 第一个参数是已经存在的一种类型,而第二个参数是自己定义的类型
这里,define 后,使用的是 define 的第一个参数,而 typedef 使用的是第二个参数
struct
C 语言的 struct 内部能不能有方法,但是可以包含其他的 struct (C++可以有方法) struct 不像类,必须在函数外,函数内也可以定义,只不过作用域局限于函数内罢了 一些通用的结构体可能会考虑定义在函数外,并且写一大堆操纵它的方法
C 支持->符号,你可以通过指针对象->的访问成员
一般,我们在。h 中定义一个结构体(反正它没函数,也不允许内部变量定义时即进行初始化赋值,必须定义对象后赋值,都一样的)操作结构提的方法的定义在。h 中,实现去。cpp 里实现
struct Mystruct{
int x;
int y;
};
int main(){
struct Mystruct obj;
struct MyStruct* ptr = &obj;
}然我们对比 C++class 来理解
class Symbol {
public:
string type;
int arrayDim;
};
Symbol symbol;C99 之后,允许使用.来对结构体初始化,可以不按顺序的赋值
obj={
.x=1,
.y=2
}//注意是逗号当我们使用->访问时,意味着->的左边是一个指针
当我们使用。访问时,意味着。的左边是一个变量
和。或->右侧的东西没有任何的关系
typedef
C 只是声明对象的时候要包含 struct。为了解决这个问题,通常与 typedef 一起使用 typedef char* String;
typedef int int_a; typedef int_a int_b; // 这是合理的,但不建议 一般要把前一个放在头文件里,后一个放在另一个头里。
typedef struct {
int x;
int y;
} Point;
Point p;这样做,声明了一个匿名结构体,然后起别名为 Point,以后使用的时候,就不用写 struct。
匿名结构体一般是放在另一个 struct 里
struct Employee {
char name[50];
int id;
struct {
int day;
int month;
int year;
} birthdate; // 匿名结构体
};
//和在外面定义后 birthdate,在引进来 struct Birthdate birthdate; 一样值得注意的是,typedef 不一定只有一个空格 比如 typedef unsigned int u_int,最后面的是你真正能够使用的
const
const int a 是常量,然而,在 C 中单独定义 const 变量没有明显的优势,可以使用#define 命令代替,尽管依然具有 define 的一些常见问题
在 C 中,常量定义时就要赋值,不允许先定义再赋值。
const 默认与其左边结合,当左边没有任何东西则与右边结合
const int *p1; //指向的数据不能改(通过该指针),指针可指向另一个东西,然后修改它也不是不行
//这和函数接收指向常量的指针一样
//即 *p1 是不可修改的 p1 可指向另一个东西
void fun(const char* str);//表示我们不准备在这个函数中修改这个指针指向的内容
//本质,只是有一个 const 的变量当作形参,它作用域是在这个函数内
int const *p2; //等效上一个,一般不用
int * const p3;
//指向指向的地址是固定的,即指针的值定死了,指向的东西可修改const 的变量直接修改会被编译器发现。使用指针+强制类型转换可以绕开。不过,const 变量编译器有额外优化,不建议修改。
inline
内联的 这个函数将在编译时展开,不使用栈结构,加快运行 不过具体是否展开要看编译器,实际上对于程序员来说,不用写,没用
unsigned
无符号 正常一个变量默认被 signed 修饰,有符号位 unsigned 没有符号位,只能表示非负数
定义与声明
对于变量来说,定义与声明是一回事 对于函数或类来说,声明不给出函数或类的成员函数的实现,可以多次重复的声明 (类的声明,就像 C++头文件对类的声明一样,只是没有函数实现) 定义则包含了函数和类的全部实现
”函数必须具有定义且应具有声明,尽管定义可用作声明(如果声明在调用函数前出现)。 函数定义包含函数主体(调用函数时执行的代码)。“
stdio 实现
printf 和 scanf 是利用了 <stdarg.h> 来实现的
int printf(const char* format, ...);
int scanf(const char* format, ...);
%c char
%s string 值得注意的是,%s 的字符串不包含空格
%d 十进制有符号整数
%f 十进制浮点数 %.2f
%p 指针的地址
现在问题无非是,只会使用 printf,但是不会使用 scanf。其实很简单,它们都需要期待一个 format,scanf 的话,必须由用户来确保标准输入和源代码里的 format 匹配上,这样,scanf 才能理解到。
%d 是整数,可以是好几位的。
scanf 需要一个地址来写入,而 printf 不需要
当你需要读取
1 2 3 1 2
你无法预知输入的个数时,你就没有办法确立一个 format string,那么就需要考虑循环
while(scanf("%d", &number)==1){
//
if(getchar()=='\n') break;
}int getchar(void);
读取一个字符,成功则返回这个字符,失败则返回 EOF
#define EOF -1
int ch;
while ((ch = getchar()) != EOF) {
printf("%c", ch);
}这段代码,在按下回车之后,能够输出。而不是一个个输出,或者 ctrl+z 才输出。
C 的赋值语句的返回值是,=号左侧的值,因此这句话的含义是先把 getchar 的返回值赋值给 ch,然后将赋值语句的返回值,实际上也就是赋值后的 ch 的值是不是 EOF。
这里是因为后续需要用到 ch 才这样写,否则不需要 ch。
while(a=1)永远真,是因为赋值语句返回值是 1
将一行输入读取到字符串数组(C)
char* gets(char* str);
返回值。成功则时实参 str,失败则是 NULL。gets 没有对您的输入的长度进行判断,因此不安全。 ß char* fgets(char* str, int count, FILE* stream);
if (fgets(line, MAX_LENGTH, stdin) != NULL) {
//读取到的内容中包含'\n'
}在 C++中,引入<sstream>,其包含 istringstream, ostringstream
对于以上问题(必须是空格分割的数字才能够使用)
首先用 getline 读一下,然后根据字符串构造 iss 对象,再循环提取到数组即可
getline(cin,s);
istringstream iss(s);
while(iss>>number){
numbers.push_back(number);
}X86 汇编
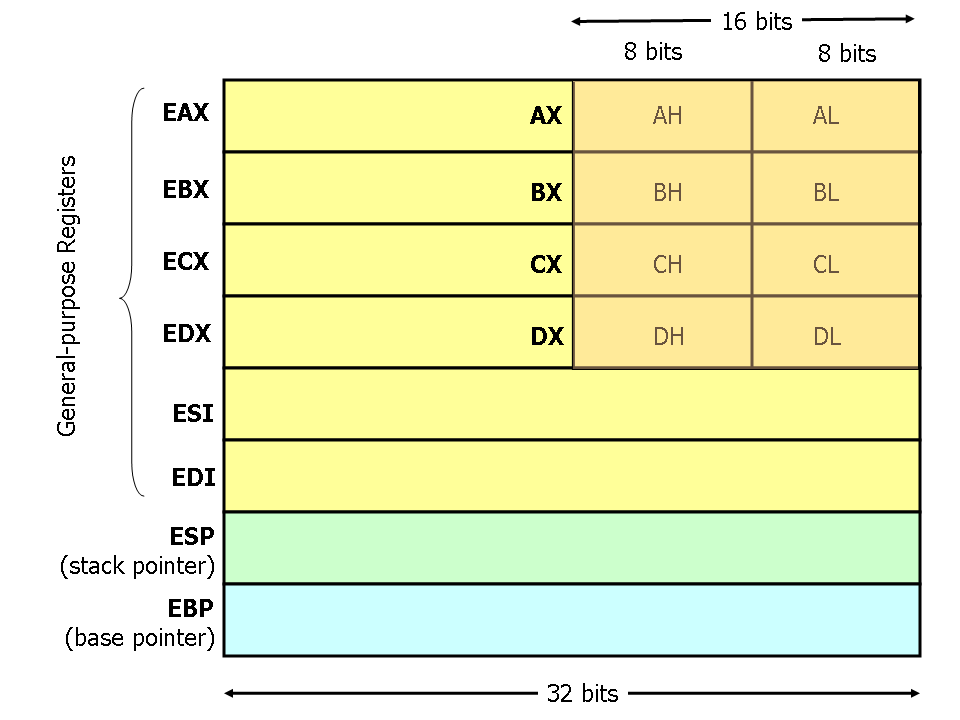
以 32 位 X86 架构 CPU 为例
寄存器
有 8 个通用寄存器
EAX 用于计算,通常是循环的 SUM
ECX 用于循环遍历计数
ESP 栈指针
EBP 基地址指针,用于函数调用
可以看到,图里面,前四个叫做 ABCD eax ebx ecx edx (划分为三段是为了兼容 16 位程序)
常用指令
MOV 移动
mov 指令将其第二个操作数引用的数据项(即寄存器内容、内存内容或常量值)复制到其第一个操作数引用的位置(即寄存器或内存)。虽然可以进行寄存器到寄存器的移动,但不能进行直接的内存到内存的移动。如果需要进行内存传输,必须先将源内存内容加载到寄存器中,然后才能将其存储到目标内存地址。
MOV AX [BX] 将内存地址是 BX 的内容,移动到寄存器 AX 里
MOV [VAR] ebx 将 EBX 的内容,移动到 VAR 的地址处 VAR 是一个常量
PUSH 推送堆栈
push 指令将其操作数放在内存中硬件支持的堆栈顶部。具体来说,push 首先将 ESP 减少 4,然后将其操作数放入地址 [ESP] 处的 32 位位置的内容中。由于 x86 堆栈向下增长 - 即堆栈从高地址向低地址增长,因此 ESP(堆栈指针)通过 push 减少。
pop 弹出堆栈
pop 指令将 4 字节数据元素从硬件支持的堆栈顶部移到指定的操作数(即寄存器或内存位置)。它首先将位于内存位置 [SP] 的 4 个字节移动到指定的寄存器或内存位置,然后将 SP 增加 4。
LEA 加载有效地址
LEA BX [AX] 将 AX 寄存器的值,作为偏移量,加载到 BX 寄存器里
lea 指令将其第二个操作数指定的地址放入其第一个操作数指定的寄存器中。请注意,不会加载内存位置的内容,只计算有效地址并将其放入寄存器中。这对于获取指向内存区域的指针很有用。
只是用来计算地址,而不是实际访问数据
但是 lea 本身是一个专门用于计算地址的指令,它的执行效率比单独分开进行加法、乘法等操作要高,而且更简洁。现代 CPU 也对 lea 做了优化,因此它在很多情况下比使用多个算术指令来计算地址更有效。